Introduction à la régression logistique
La régression logistique est une méthode statistique utilisée pour modéliser la probabilité qu’un événement se produise en fonction de variables explicatives. Contrairement à la régression linéaire, qui prédit une valeur continue, la régression logistique est utilisée pour des variables dépendantes catégorielles binaires (oui/non, succès/échec).
Fonctionnement de la régression logistique
Formule de base
La régression logistique se base sur la fonction logistique, également appelée fonction sigmoïde, définie comme suit :
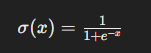
Dans le contexte de la régression logistique, cette fonction permet de transformer n’importe quelle valeur réelle en une probabilité comprise entre 0 et 1.
Modèle de régression logistique
Le modèle de régression logistique prend la forme suivante :
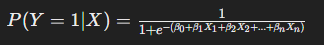
Où :
- P(Y=1∣X) est la probabilité que l’événement Y=1 se produise étant donné les variables explicatives X.
- β0 est l’ordonnée à l’origine (intercept).
- β1,β2,…,βn sont les coefficients des variables explicatives X1,X2,…,Xn
Interprétation des coefficients
Les coefficients de la régression logistique (β) représentent l’effet des variables explicatives sur la probabilité de l’événement. Par exemple, un coefficient positif signifie qu’une augmentation de la variable explicative augmente la probabilité que l’événement se produise.
Applications pratiques de la régression logistique
Secteur médical
Dans le domaine de la santé, la régression logistique est couramment utilisée pour prédire la probabilité de maladies en fonction de facteurs de risque. Par exemple, elle peut estimer la probabilité qu’un patient développe une maladie cardiaque en fonction de l’âge, du sexe, du taux de cholestérol, etc.
Marketing
Les spécialistes du marketing utilisent la régression logistique pour prévoir la probabilité qu’un client achète un produit en fonction de ses caractéristiques démographiques, de son historique d’achat, et de son comportement en ligne. Cela permet de cibler efficacement les campagnes publicitaires.
Finance
En finance, la régression logistique est utilisée pour évaluer le risque de défaut de paiement d’un emprunteur. Les variables explicatives peuvent inclure le revenu, l’historique de crédit, et d’autres facteurs économiques.
Sécurité
Dans le domaine de la sécurité, cette technique peut aider à détecter les fraudes en analysant les transactions et en identifiant celles qui ont une probabilité élevée d’être frauduleuses.
Exemple simple pour illustrer la régression logistique
Imaginons que nous souhaitions prédire si un étudiant réussira un examen (succès = 1, échec = 0) en fonction du nombre d’heures d’étude.
- X : nombre d’heures d’étude
- Y : réussite à l’examen (1 = succès, 0 = échec)
Nous avons les données suivantes :
- Étudiant 1 : 2 heures, échec
- Étudiant 2 : 3 heures, échec
- Étudiant 3 : 5 heures, succès
- Étudiant 4 : 7 heures, succès
Après avoir appliqué la régression logistique, nous obtenons un modèle qui pourrait ressembler à ceci :
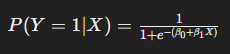
Supposons que les coefficients estimés soient β0=−2et β1=0,8
Pour un étudiant qui étudie 4 heures, la probabilité de réussir est :
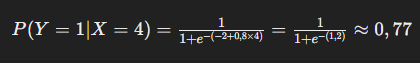
Cela signifie qu’un étudiant qui étudie 4 heures a environ 77% de chances de réussir l’examen.
Conclusion
La régression logistique est un outil puissant et polyvalent pour la prédiction de variables binaires. En comprenant les principes de base et les applications pratiques, on peut l’utiliser efficacement dans divers domaines tels que la médecine, le marketing, la finance et la sécurité. Sa capacité à transformer des données complexes en probabilités interprétables en fait un allié précieux pour la prise de décision basée sur les données.
0 commentaire