ChatGPT est capable de génerer un grand nombre de taches sur tout ce qui touche au contenu (génération, résumé, optimisation, reformulation,…)
Mais il y a un autre domaine où il peut s’avérer redoutable : la génération de code.
Je me suis amusé à lui demander de me créer un crawler en langage R.
Comment faire ?
Je suis parti du prompt suivant que j’ai éxecuté avec GPT4 :
Tu es un dev R expérimenté
Donne moi le script R pour réaliser un crawler
A partir d'une url tu vas découvrir toutes les pages d'un sites
Tu stockeras tous les liens dans un data frame links (contenant l'url de la page source, l'url de la page destination, l'ancre du lien
Et le code html des pages dans le data frame pages
Transforme les liens relatifs en liens absolus
Gère les erreurs 404,500 et les autres
Affiche moi un % d'avancement
Ne crawle que les liens internes
Il m’a généré un script que j’ai ensuite exécuté.
Comme toujours lorsqu’on lui demande des taches complexes j’avais quelques erreurs que je lui ai remonté afin qu’il me génère une nouvelle version du code prenant en compte l’erreur rencontrée
Le résultat
Au bout de quelques aller retour pour lui faire corriger mon script, j’ai pu lancer un crawl complet.
L’avancement du crawl
Pendant l’exécution, j’ai un suivi d’avancement :
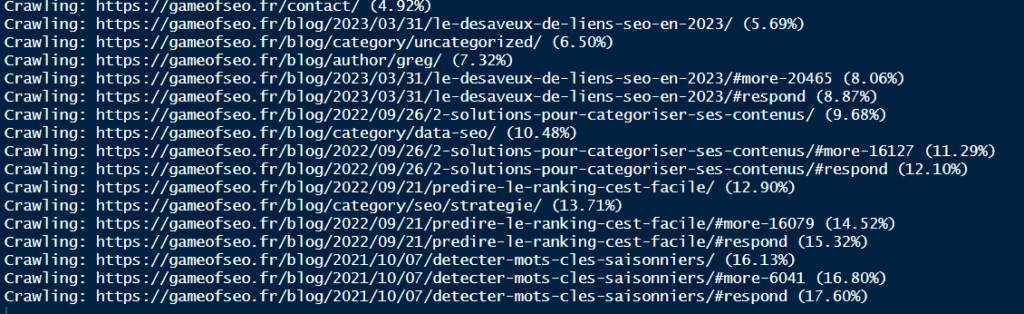
Je peux facilement voir le pourcentage de pages traitées par rapport à celles qu’il connait.
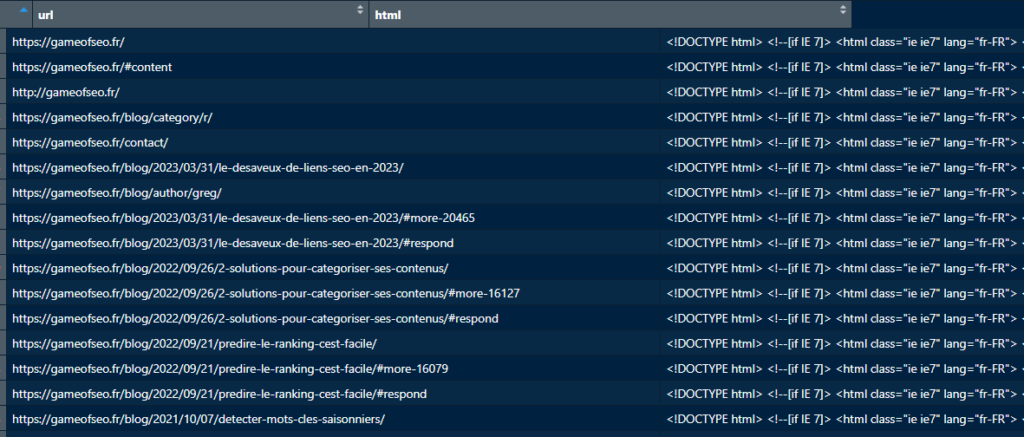
Les pages découvertes
Voici la liste des pages qu’il a découvert pour le site gameofseo.fr.
Je lui ai demandé de me stocker le code HTML, ce qui me permettra dans un seconde temps d’analyser les différentes balises SEO (title, meta, canonical, voire d’analyser la sémantique des contenus)
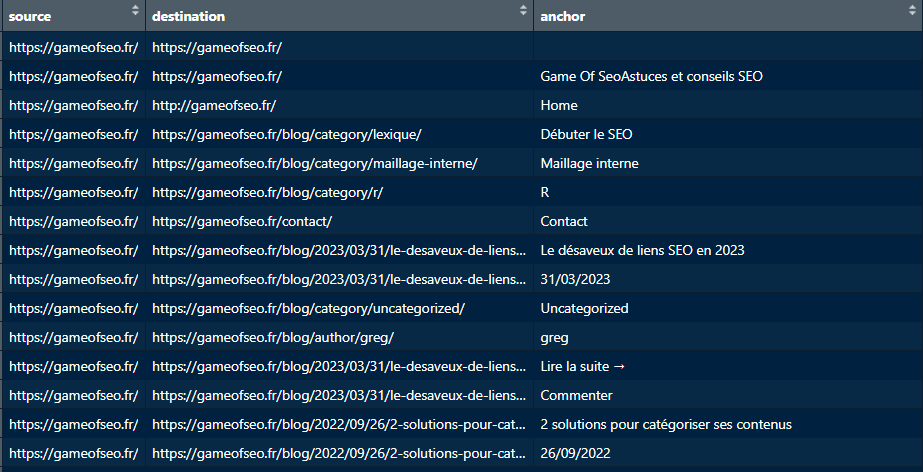
Les liens entre les pages
Et j’ai également à ma dispo la liste des liens internes qu’il a trouvé avec l’ancre associée :
Le code final généré par chat GPT
library(rvest)
library(dplyr)
library(urltools)
# Initial URL
start_url <- "https://gameofseo.fr/"
domain <- domain(start_url)
# Data frames to store the links and pages
links <- data.frame(source = character(), destination = character(), anchor = character(), stringsAsFactors = FALSE)
pages <- data.frame(url = character(), html = character(), stringsAsFactors = FALSE)
# Queue of URLs to crawl
queue <- c(start_url)
visited <- c()
while (length(queue) > 0) {
url <- queue[1]
queue <- queue[-1]
visited <- c(visited, url)
# Display progress
cat(sprintf("Crawling: %s (%.2f%%)\n", url, length(visited) / (length(visited) + length(queue)) * 100))
# Try to read the page
try({
page <- read_html(url)
# Store the page HTML
pages <- rbind(pages, data.frame(url = url, html = as.character(page), stringsAsFactors = FALSE))
# Extract the links
anchors <- html_nodes(page, "a")
hrefs <- html_attr(anchors, "href")
texts <- html_text(anchors)
# Process the links
for (i in seq_along(hrefs)) {
href <- hrefs[i]
text <- texts[i]
# Handle relative links
if (startsWith(href, "/")) {
href <- paste0(scheme(url), "://", domain, href)
}
# Only crawl internal links if the domain is valid
if (!is.na(domain(href)) && domain(href) == domain) {
links <- rbind(links, data.frame(source = url, destination = href, anchor = text, stringsAsFactors = FALSE))
if (!(href %in% visited) && !(href %in% queue)) {
queue <- c(queue, href)
}
}
}
}, silent = TRUE)
}
Conclusion
Le résultat n’est pas immédiat car Chat GPT a parfois du mal à gérer toutes les exceptions qui peuvent se produire. Parfois il a également tendance à inventer des instructions qui n’existent pas (mais si on lui remonte l’erreur, il sera souvent capable de la corriger)
A titre perso, je l’utilise de plus en plus pour développer plus rapidement : pour des taches simples, il fournit assez souvent un code qui fonctionne.

3 commentaires
zonetuto · 18/08/2023 à 10:36
Je me suis fait le mien en php, si on connaît le métier on gagne un temps fou
Seopulse · 20/08/2023 à 08:38
C’est super pratique je l’avoue :). Je suis pas dev et j’ai joué avec sur du Python, c’est impressionnant quand même. Et les commentaires des actions sont une aides précieuse.
Pour faire un audit seo de site, très rapide, cela vaut le coup.
SEO Consultant | Manda · 20/08/2023 à 14:13
Il est fascinant de voir à quel point ChatGPT est polyvalent et capable de générer une multitude de tâches, y compris dans le domaine de la génération de code. Votre expérience avec la création d’un crawler en langage R est une démonstration impressionnante de ses compétences.
La façon dont vous avez formulé vos instructions pour générer le script R de création d’un crawler est remarquable. La capacité de ChatGPT à comprendre et à répondre à des instructions complexes est vraiment impressionnante. Le processus que vous avez suivi, en échangeant avec ChatGPT pour affiner le script en fonction des erreurs rencontrées, montre comment il peut s’adapter et apprendre de ses erreurs pour produire un code fonctionnel.
Le résultat final, un crawl complet réussi, est la preuve concrète de l’utilité de ChatGPT dans le développement de projets techniques. Cela ouvre des perspectives intéressantes pour la collaboration entre les développeurs et les outils basés sur l’intelligence artificielle pour la création et l’amélioration de solutions informatiques. Bravo pour avoir exploré cette facette de ChatGPT et pour avoir obtenu des résultats concrets grâce à cette collaboration.