Nouvel exemple de ce qu’on peut faire en utilisant le langage R. Cette fois çi nous allons nous pencher sur une analyse sémantique construite à partir d’une base de mots clés. Cette analyse est très utile pour prioriser les contenus à produire en fonction de leur potentiel de trafic SEO
Qu’est ce qu’une co-occurrence ?
Une co-occurrence est un terme souvent associé à un autre. Par exemple « mariée » et souvent associé à « robe ». L’identification des co-occurrence est possible grâce à l’analyse sémantique d’un corpus (ensemble de documents).
A quoi ça sert ce type d’analyses ?
Le détection de co-occurrence va vous permettre d’identifier des contenus à produire.
Ici nous allons pondérer les co-occurences en fonction des volumes de recherche. Ce qui va nous permettre
- de prioriser les contenus à créer
- d’optimiser la sémantique de nos pages déjà existantes
Dans le but de maximiser nos chances côté SEO
L’analyse
Récupérer les données
La première étape consiste à exporter une liste de mots clés. Pour cette exemple j’ai exporté la liste des mots clé contenant l’expression « matelas ».
J’ai récupéré cette liste à partir de l’outil Semrush.
Installer les packages
[pastacode lang= »java » manual= »install.packages(%22tm%22)%0Ainstall.packages(%22wordcloud%22)%0Ainstall.packages(%22RColorBrewer%22)%0Ainstall.packages(%22dplyr%22)%0A » message= » » highlight= » » provider= »manual »/]
- « tm » est un package destiné au texte mining
- « wordcloud » va me permettre de mettre en forme mes résultats sous forme de tagcloud
- « RColorBrewer » va nous permettre de mettre tout ça en couleur
- « dplyr » permet de manipuler les données
L’installation des package n’est a réaliser qu’une fois.
Charger les packages
[pastacode lang= »java » manual= »library(%22wordcloud%22)%0Alibrary(%22RColorBrewer%22)%0Alibrary(%22tm%22)%0Alibrary(%22dplyr%22)%0A » message= » » highlight= » » provider= »manual »/]
Pour pouvoir utiliser un package, il faut le charger.
Chargement des données
[pastacode lang= »java » manual= »%23Je%20charge%20le%20fichier%0Akeywords%20%3C-%20read.csv(file%3D%22C%3A%2FUsers%2Fgreg%2FDownloads%2Fmatelas-phrase_fullsearch-fr.csv%22%2C%20header%3DTRUE%2C%20sep%3D%22%3B%22%2Cencoding%20%3D%20%22UTF-8%22)%0A%0A%23%20Je%20filtre%20pour%20%C3%A9viter%20le%20bruit%0A%23keywords%20%3C-%20filter(keywords%2C%20keywords%24Search.Volume%20%3E300)%0A » message= » » highlight= » » provider= »manual »/]
- Je charge les données
- Je filtre pour éviter d’avoir trop d’éléments : je ne garde que les mots clés recherchés plus de 300 fois par mois ( à adapter en fonction du mots clé analysé)
Création du corpus
[pastacode lang= »java » manual= »%23%20Je%20cr%C3%A9e%20un%20corpus%0AdfCorpus%20%3D%20Corpus(VectorSource(keywords%24Keyword))%20%0Adtm%20%3C-%20TermDocumentMatrix(dfCorpus)%0A%0Am%20%3C-%20as.matrix(dtm)%0Av%20%3C-%20sort(rowSums(m)%2Cdecreasing%3DTRUE)%0A%0Amots%20%3C-%20data.frame(word%20%3D%20names(v))%0A » message= » » highlight= » » provider= »manual »/]
- Je crée un corpus à partir de ma liste de mots clés
- Je récupère tous les mots contenu dans ma liste de mots clés
Nettoyage
[pastacode lang= »java » manual= »%23%20Je%20retire%20les%20termes%20contenus%20dans%20ma%20recherche%0Amots%20%3C-%20filter(mots%2C!grepl(%22matel%22%2Cmots%24word))%0A » message= » » highlight= » » provider= »manual »/]
Je retire l’expression de départ ainsi que ses dérivés (lemmes) : « matel »
Cela me permet de donner plus de poids aux autres expressions.
Je calcule le score de chaque mot
[pastacode lang= »java » manual= »%23%20je%20calcule%20le%20score%0Afor%20(%20i%20in%201%3Anrow(mots))%0A%7B%0A%20%20listeExpressionAvec%20%3C-%20filter(keywords%2C%20grepl(paste(%22%5E%22%2Cmots%24word%5Bi%5D%2C%22%20%7C%20%22%2Cmots%24word%5Bi%5D%2C%22%20%7C%20%22%2Cmots%24word%5Bi%5D%2C%22%24%22%2Csep%3D%22%22)%2Ckeywords%24Keyword))%0A%20%20score%20%3C-%20as.integer(summarise(listeExpressionAvec%2CvolumeRecherche%20%3D%20sum(listeExpressionAvec%24Search.Volume))%5B1%5D)%0A%20%20%0A%20%20mots%24score%5Bi%5D%20%3C-%20score%0A%7D%0A » message= » » highlight= » » provider= »manual »/]
Pour chaque mot :
- Je retrouve les expressions qui le compose
- Je calcule le score : somme de volumes de recherche des expressions comportant un mot donné
Je génère mon tagcloud
[pastacode lang= »java » manual= »%23%20Je%20g%C3%A9n%C3%A8re%20mon%20tagcloud%0Aset.seed(1234)%0Awordcloud(words%20%3D%20mots%24word%2C%20freq%20%3D%20mots%24score%2C%20min.freq%20%3D%201%2C%0A%20%20%20%20%20%20%20%20%20%20max.words%3D200%2C%20random.order%3DFALSE%2C%20rot.per%3D0.35%2C%20%0A%20%20%20%20%20%20%20%20%20%20colors%3Dbrewer.pal(8%2C%20%22Dark2%22))%0A » message= » » highlight= » » provider= »manual »/]
Le résultat
Je récupère un joli tagcloud avec tous les termes associés au mot clé que j’ai souhaité analyser. Visuellement c’est simple à analyser.
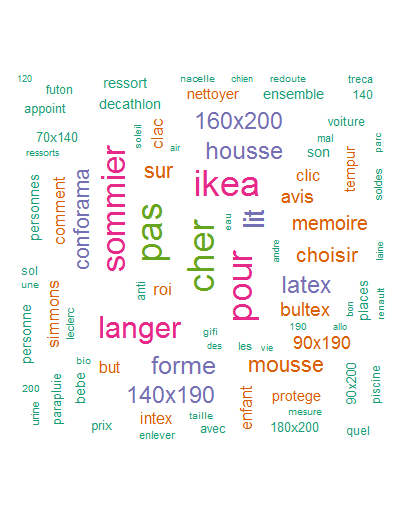 Plus un mot est gros plus il est fréquemment associé au mot clé « matelas » dans les recherches des internautes sur Google.
Plus un mot est gros plus il est fréquemment associé au mot clé « matelas » dans les recherches des internautes sur Google.
Conclusion
Encore une fois, avec un script assez court, on arrive à automatiser une action qui peut prendre du temps, surtout si on réalise plusieurs fois la même analyse.
Ce type d’analyse est vraiment utile pour :
- Définir les contenus / pages à créer
- Créer le contenu de vos fiches produits
- Créer un cocon sémantique ( ici je conseille de faire une analyse par niveau)
Le must serait de récupérer les données via l’API de semrush pour ne plus avoir à faire d’export manuel 😉
Le script complet
[pastacode lang= »java » manual= »%23%20Installer%0A%23install.packages(%22tm%22)%20%20%23%20pour%20le%20text%20mining%0A%23install.packages(%22SnowballC%22)%20%23%20pour%20le%20text%20stemming%0A%23install.packages(%22wordcloud%22)%20%23%20g%C3%A9n%C3%A9rateur%20de%20word-cloud%20%0A%23install.packages(%22RColorBrewer%22)%20%23%20Palettes%20de%20couleurs%0A%23install.packages(%22dplyr%22)%20%23%20Palettes%20de%20couleurs%0A%0A%23%20Charger%0A%0Alibrary(%22wordcloud%22)%0Alibrary(%22RColorBrewer%22)%0Alibrary(%22tm%22)%0Alibrary(%22dplyr%22)%0A%0A%23Je%20charge%20le%20fichier%0Akeywords%20%3C-%20read.csv(file%3D%22C%3A%2FUsers%2Fgreg%2FDownloads%2Fmatelas-phrase_fullsearch-fr.csv%22%2C%20header%3DTRUE%2C%20sep%3D%22%3B%22%2Cencoding%20%3D%20%22UTF-8%22)%0A%0A%23%20Je%20filtre%20pour%20%C3%A9viter%20le%20bruit%0A%23keywords%20%3C-%20filter(keywords%2C%20keywords%24Search.Volume%20%3E300)%0A%0A%0A%23%20Je%20cr%C3%A9e%20un%20corpus%0AdfCorpus%20%3D%20Corpus(VectorSource(keywords%24Keyword))%20%0Adtm%20%3C-%20TermDocumentMatrix(dfCorpus)%0A%0Am%20%3C-%20as.matrix(dtm)%0Av%20%3C-%20sort(rowSums(m)%2Cdecreasing%3DTRUE)%0A%0Amots%20%3C-%20data.frame(word%20%3D%20names(v))%0A%0A%23%20Je%20retire%20les%20termes%20contenus%20dans%20ma%20recherche%0Amots%20%3C-%20filter(mots%2C!grepl(%22matel%22%2Cmots%24word))%0A%0A%23%20je%20calcule%20le%20score%0Afor%20(%20i%20in%201%3Anrow(mots))%0A%7B%0A%20%20listeExpressionAvec%20%3C-%20filter(keywords%2C%20grepl(paste(%22%5E%22%2Cmots%24word%5Bi%5D%2C%22%20%7C%20%22%2Cmots%24word%5Bi%5D%2C%22%20%7C%20%22%2Cmots%24word%5Bi%5D%2C%22%24%22%2Csep%3D%22%22)%2Ckeywords%24Keyword))%0A%20%20score%20%3C-%20as.integer(summarise(listeExpressionAvec%2CvolumeRecherche%20%3D%20sum(listeExpressionAvec%24Search.Volume))%5B1%5D)%0A%20%20%0A%20%20mots%24score%5Bi%5D%20%3C-%20score%0A%7D%0A%0A%23%20Je%20g%C3%A9n%C3%A8re%20mon%20tagcloud%0Aset.seed(1234)%0Awordcloud(words%20%3D%20mots%24word%2C%20freq%20%3D%20mots%24score%2C%20min.freq%20%3D%201%2C%0A%20%20%20%20%20%20%20%20%20%20max.words%3D200%2C%20random.order%3DFALSE%2C%20rot.per%3D0.35%2C%20%0A%20%20%20%20%20%20%20%20%20%20colors%3Dbrewer.pal(8%2C%20%22Dark2%22))%0A%0A%0A » message= » » highlight= » » provider= »manual »/]
Comme d’habitude n’hésitez pas à commenter / partager cet article.



5 commentaires
Dadoo · 04/05/2017 à 16:42
Genial et astucieux
Merci
Le Steve · 12/05/2017 à 09:54
Très très bonne démonstration de l’Intérêt de R, je partage !
laurent · 26/05/2018 à 11:51
pour ceux qui n utilise pas semrush un model d export csv aurai été bien
excellent cette article
continue comme sa je suis fan
Anne-Sophie · 08/01/2019 à 17:28
Bonjour, merci pour cet article et bien d’autres 😉
Pourriez-vous me préciser quelque chose. Je ne suis pas spécialement familière avec R, mais j’ambitionne de le devenir. J’ai suivi votre tuto à la lettre. Je ne pense pas avoir fait d’erreurs, mais cela vient certainement de mon utilisation avec RStudio. Pourriez vous s’il vous plait m’éclairer sur la démarche à suivre dans RStudio.
Un grand merci par avance
greg · 14/01/2019 à 15:46
Bonjour,
il suffit de sélectionner tous le code source, le copier coller dans R studio, vous pouvez ensuite l’exécuter.
Grégory